Search Docs by Keyword
Data Storage Workflow
Overview
The FASRC Compute Cluster is a complex place. There are many different compute partitions and storage options to choose from, and this is even before you add your own complexity of your code, data, and other computational work. Some of this complexity is necessary, but some is not. We hope that the following guide will help you organize your data on a cluster in a way that is easy to manage and locate. This best practices guide will not necessarily work for every workflow, but rather is intended as a simple starting point.
Storage Types
First, it will be helpful to classify the different types of storage you will be using on the cluster. Knowing about the different types of storage and their architecture will help you better adjudicate where to put different types of data. Understanding the basic cluster workflow is also helpful. Later we will provide specific suggestions for the different classes of storage.
Broadly speaking the cluster can be organized in to four classes of storage:
- Home Directories: Home directories are those folders that you start in when you log in. They contain all the necessary system files needed to customize your specific environment. These home directories are small and resilient (e.g. have snapshots and backups).
- Lab Directories/Tiered Storage (Tier 0-2): Lab directories and Tiered Storage are storage space for a specific lab. This storage varies in type and style but is built for long term storage for a lab. For the sake of the below discussion we will refer to this generally as Lab Storage.
- Scratch Directories: Scratch directories are those folders which are intended for temporary data storage on the cluster. There are two types of scratch, “global scratch” which is available on every node on the cluster and “local scratch” which is tied to the specific node. Global scratch is subject to our scratch policy, while local scratch is only extant for the duration of your job. This space is not backed up or snapshotted. The global scratch has a very large amount of space and is built for performance, while local scratch is more limited but has the best performance on the cluster.
- Tier 3 Storage: Tier 3 storage is storage that the Lab has purchased which is intended for data that needs to be kept around but is not actively needed now.
When you use the cluster the commonly expected workflow is shown in the diagram below and described as follows:
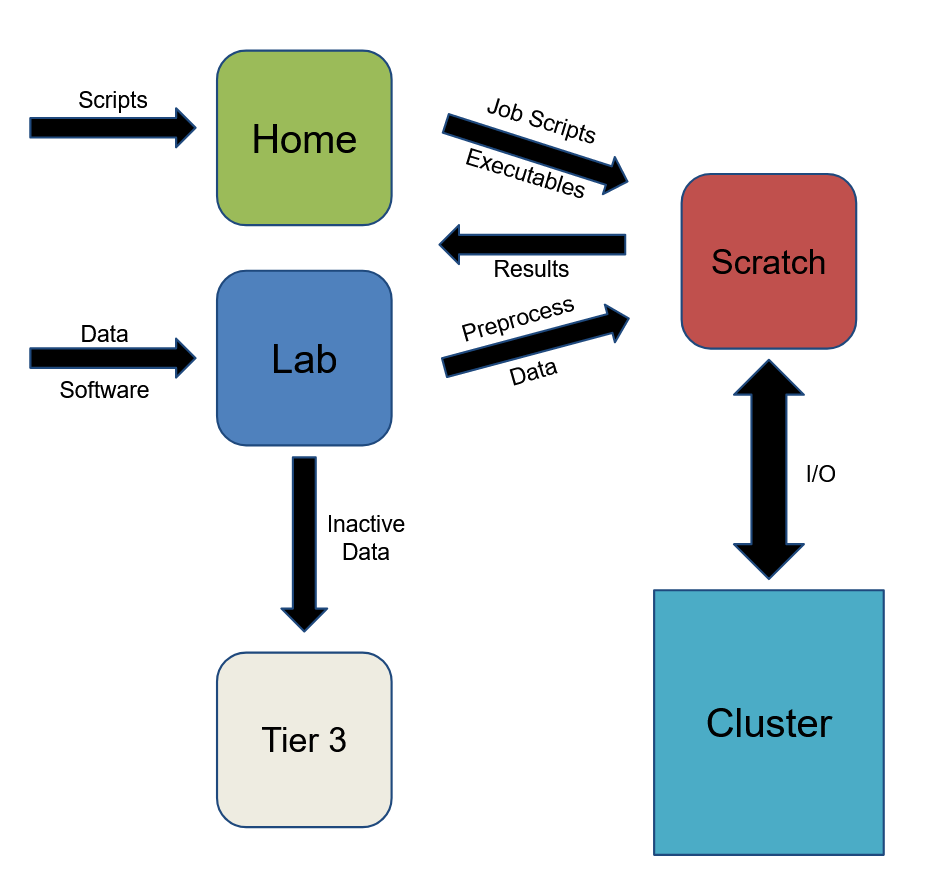
- Your initial scripts go into your home directory.
- Your data and software go into your lab storage.
- When you are ready to run on the cluster you move the data, scripts, and executables you need to scratch.
- You compute against scratch.
- You transfer the data you want to save back to lab storage.
- You move any inactive data to Tier 3 storage.
Naturally workflows can get more complex but this schematic generally illustrates where different classes of data should go. Namely:
- Scripts: Home directory
- Software: Lab storage
- Data: Lab storage
- Data necessary for computation: Scratch
- Inactive Data: Tier 3
In the next section we will discuss how best to organize your data in these various general classes of storage.
Home Directory
Since home directories are small in size but highly resilient one should only put in them the data you absolutely cannot lose. This includes things like important scripts and custom software, as well as essential data necessary for your work. As a general rule all scripts and custom written code should be under version control using a software like git, and that repository should have an external copy at either github or code.harvard.edu.
One should be careful what they put in their home directory as if you fill up your home directory you will not be able to login and various other applications (like Open OnDemand) will not work. Also while the home directories are resilient they are not performant. Thus anything requiring speed should not be kept in the home directory, or at least what is in the home directory is a redundant copy of an active copy on other storage. Home directories are also locked down to a specific user so things that are intended to be shared with other users must go in other locations.
In terms of basic organization it is recommended that you make several basic folders for various classes of data. Some suggested directories are:
software: For software installs to your home directorycode: For source code repositoriespapers: For papers you’ve written or are relevant to your workscripts: For various utility scripts you have put together or find useful
Lab Storage
Most of your data will live in your lab storage by fact of its size and scope. To start we have provided a basic initial organization, this is both for security and also to enable Globus data transfers. The initial organization is as follows:
Users: These directories are locked down to the specific user and cannot be opened to other users.Lab: These directories are visible to anyone in the lab.Everyone: These directories are visible to anyone on the cluster.
In general you want to operate out of the Lab directory as it makes it easier to collaborate and utilize your data after you leave the group. Users should only be used for things you do not want the rest of your lab to see. For cross lab collaboration the Everyone directory should be used.
Similar to the Home directories you should make basic folders for various classes of data. Some suggested directories are:
software: For software installs common to the lab.scripts: For various utility scripts common to the lab.<projectname>: For specific lab projects.<username>: For specific user code or data.
General rules to follow:
- Avoid file or directory names with spaces or special characters (including but not limited to:
(<{[!@#$%^&*?|\]}>)). - Avoid camel casing (
ExAmPle) or capslock in filenames and directory names. Simply use all lower case. - Keep number of files in a single directory under 10,000. If you need to have more, you should shard your data into subdirectories.
- Keep redundant copies of important data or scripts on other filesystems. This is especially important for storage that has no snapshots.
- Do not duplicate data on the storage needlessly. For large datasets have a single copy commonly used by the lab set to read only.
- Compress, move, or remove old and unused data. Only active data should be on Lab storage.
Global Scratch
Global scratch (or networked scratch) is intended for users to compute against. Speed and capacity is of primary concern. As such users should not keep important data on global scratch but rather only keep that data you need to do your calculations and then move any data you want to save back to your Lab space.
Many of the same rules and organization should be followed as the Lab Storage. Some additional rules for global scratch:
- Avoid having all your jobs reading or writing to a single file. Instead consider making redundant copies of the file and sharding your jobs so that bunches of 10-100 jobs hit one of the copies (i.e. Jobs 1-100 hit copy 1, jobs 101-200 hit copy 2).
- (Lustre specific) Consider striping large files over multiple OST’s using Lustre striping. This only applies to new files in a directory you have set to stripe, existing files will remain as is. Thus you should set up a directory that is striped and then copy the data (not
mv) into that directory. We recommend 1M for the stripe size and count should be 8 or more. - If possible move files you will be constantly reading and writing to local
/scratch. The performance will be better. If you do so be sure to move data you want to save from/scratchto global scratch or lab storage before the job exits as data in local scratch only lasts for the job.
Local Scratch
Local scratch is local disk on compute nodes set aside for users to compute against. This space can be found at /scratch. Local scratch has the highest performance but is limited to the node itself and for the duration of the job. As such users should not keep important data on local scratch but rather only keep that data you need to do your calculations and then move any data you want to save back to your Lab space. This should be done at the end of the job as data will be removed from /scratch after the job ends.
Many of the same rules and organization should be followed as the Lab Storage. Some additional rules for local scratch:
- If your job is constantly reading and writing then using local scratch will be your fastest storage path. We recommend copying the data you need to local scratch once at the start of the computation and then copying the data you want to save once at the end of the computation.
- While we do automatically clean up local scratch after each job, it is best if you clean up after yourself after your calculation is complete to ensure you got everything off the local scratch.
- To avoid naming collisions (as multiple of your jobs could run on the same node) name the initial folder you create in local scratch after the JobID of the job or some other unique name for the job.
- Consider using the
--tmpoption to tell the scheduler how much local scratch storage you need. This is especially true if you need a significant amount of space. Local scratch sizes vary widely between nodes with some having as little as 70G and other have over 1TB of local scratch. Using the--tmpflag will ensure that you end up on a node with local scratch. You can find how much local storage a node has by looking at theTmpDiskcategory under the node description in slurm.
Tier 3
This storage should be used for inactive data. For best practices see the Tier 3 documentation.
Bookmarkable Section Links