Search Docs by Keyword
IQSS: Differences between the RCE and FASRC Clusters
The RCE has been scheduled for decommission on November 1, 2022. Sometime after that date, this document will become obsolete.
If you have never used the RCE
If you have never used IQSS’s RCE (Research Computing Environment cluster), you can skip reading this document.
Goal of this document
The documentation about the clusters run by FASRC – CANNON and FASSE – are primarily written for users in the “hard sciences” and rarely explain the technical terminology in a way that’s accessible to users in the “soft sciences”. This document is intended to help.
Compared to the RCE, both CANNON and FASSE are newer, more powerful, and have more computing resources: CPUs, RAM, and GPUs (general purpose Graphics Processing Units). CANNON and FASSE have more applications as well as more and newer versions of applications, in part because physical sciences researchers have different needs compared to social scientists.
If you have been using the RCE
You’ve been using the RCE and now you’re being moved to CANNON or FASSE.
CANNON (named after the Harvard astronomer Annie Jump Cannon) can be used with Data Security Level 1 (DSL1, Public Information) and Data Security Level 2 (DSL2, Low Risk) materials.
FASSE (FAS Secure Environment) can be used with Data Security Level 1 (DSL1), Data Security Level 2 (DSL2), and especially Data Security Level 3 (DSL3, Medium Risk) materials.
If you need to use Data Security Level 4 (DSL4, High Risk) materials, your project must contact Support and fund the creation of a custom environment.
No cluster at Harvard is rated for Data Security Level 5 (DSL5, Extreme Risk) materials.
See Information Security Policy for the official descriptions of Data Security Levels.
Transferring files
Moving data to FASSE and/or CANNON is the same as moving data to the RCE. See the articles on Filezilla, rsync, Globus, etc.
Note that you cannot move data directly between CANNON and FASSE.
Main Differences between RCE and CANNON/FASSE
VPN (Virtual Private Network)
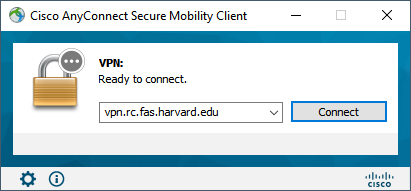
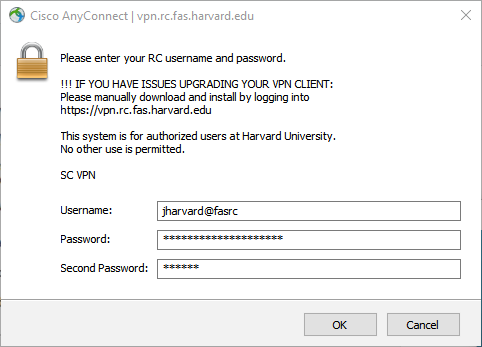
In the same way you reached the RCE, in order to reach CANNON you must connect to the VPN (vpn.rc.fas.harvard.edu) using your username and the @fasrc realm (e.g. with jharvard@fasrc). Realms provide access to different environments.
To connect to the VPN, you must also provide your password and a 2-Factor Authentication code.
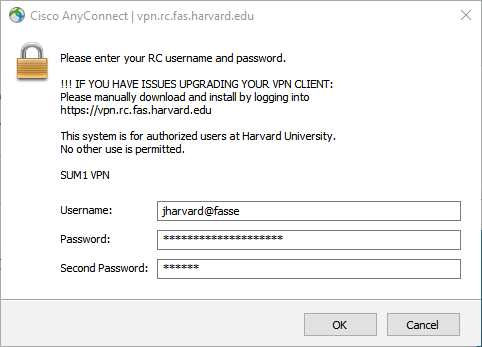
In the same way you reached the RCE, in order to reach FASSE you must connect to the VPN (vpn.rc.fas.harvard.edu) using your username and the @fasse realm (e.g. with jharvard@fasse). Realms provide access to different environments. You cannot reach FASSE from the @fasrc realm! (Similarly, you cannot reach CANNON from the @fasse realm!)
Username and Password
You cannot access CANNON or FASSE with the username and password that you used to access the RCE.
You access CANNON and/or FASSE with the same username that you use for the VPN – e.g. jharvard without the @realm – and the same password. You do not need to provide a 2-Factor Authentication code.
Note: This is NOT your HarvardKey username and password!
Partitions and Time limit for jobs
On the RCE, you did not choose a partition. The cluster resources — Memory (GB) and CPU (cores) — that you specified when launching your chosen application were used by the job scheduler to pick a computer in the cluster that was available and capable of running the application. On CANNON and FASSE, things are a little more complicated.
The RCE had no runtime (duration) limit. Most partitions on CANNON and FASSE have 7-day time limits, a couple have just 8-hour time limits, and a very few have no time limit.
For more information about partitions, see IQSS: How to Specify Resources and Choose a Cluster Partition. There are other FASRC DOCS, too.
User interface
There were 3 choices of user interface for using the RCE:
- Remote desktop (using a web browser with the NX Web Player or the NX NoMachine desktop application)
- Secure Shell (SSH) command line interface (using the Mac terminal or PuTTY on Windows) to
rce.hmdc.harvard.edu(see Accessing the RCE) - File Access / file transfer (using FileZilla or other software)
Your choices for using CANNON and FASSE include:
- the cluster’s
dashboard, a graphical user interface for launching applications including remote desktop- CANNON’s dashboard (You must be connected to the VPN with the @fasrc realm to reach CANNON’s dashboard.)
- FASSE’s dashboard (You must be connected to the VPN with the @fasse realm to reach FASSE’s dashboard.)
- Secure Shell (SSH) command line interface using the Mac terminal or PuTTY on Windows
- on CANNON at
login.rc.fas.harvard.edu(see Command line access using a terminal) - on FASSE at
fasselogin.rc.fas.harvard.edu(see the Command Line Access section in FASSE Cluster – FAS Secure Environment)
- on CANNON at
- File Access / file transfer using FileZilla or other software (see SFTP file transfer using Filezilla (Mac/Windows/Linux))
- for CANNON connect to
login.rc.fas.harvard.edu - for FASSE connect to
fasselogin.rc.fas.harvard.edu
- for CANNON connect to
Home directories, Storage Tiers, Annual Costs, and Backups
Home directories on the RCE were 2 GB because users were encouraged to have separate project directories for anything larger.
Users on CANNON and FASSE have 100 GB home directories. You can also use project directories for larger data and collaborative work. Your PI is billed for your data storage in project directories.
Home directories on CANNON and FASSE are backed up frequently. Some project directories are backed up while others are not.
This information comes from the FASRC document Storage Service Center. The table contains the prices as of August 2022.
| Tier 0 | Tier 1 | Tier 2 | Tier 3 | |
|---|---|---|---|---|
| Description | Project directories | Home directories and project directories |
Custom project directories |
Cold storage (on tape) |
| Cost per TB/month | $4.16 | $20.83 | $8.33 | $0.416 |
| Snapshots ? | No | Yes | No | No |
| Disaster Recovery ? | No | Yes | Yes | No |
| High Availability | Yes | Yes | No | Yes |
(Snapshots and Disaster Recovery refer to specific types of backups. High Availability refers to the hardware used to implement the storage. For more information, see Storage Types – Tier 0, Storage Types – Tier 1, Storage Types – Tier 2, and/or Storage Types – Tier 3.)
Job Scheduler
The job scheduler for the RCE was HTCondor, referred to here as just Condor. (See Running Batch Jobs.)
The job scheduler for both CANNON and FASSE is the Slurm Workload Manager, commonly called just Slurm. (See > Running Jobs for CANNON and FASSE Cluster – FAS Secure Environment for FASSE.)
The differences between Condor and Slurm only really matter if you manually submit jobs from the command line interface. Neither job scheduler is covered in detail in these IQSS documents. If you need to submit jobs manually from the command line interface, contact Support for personalized assistance.
Partitions
Partitions are part of how a cluster makes its resources available to users.
The RCE functioned like a single partition.
FASSE and CANNON have multiple partitions, each with different attributes. Here is a brief look at the partitions on CANNON and FASSE:
| Partitions’ key attributes | CANNON’s partition name | FASSE’s partition name |
| maximum runtime is 07-00:00 (7 days) | shared |
fasse |
| no time limit | unrestricted |
(n/a) |
| large amounts of memory | bigmem |
fasse_bigmem |
| with GPUs (General Purpose Graphical Processing Units) |
gpu |
fasse_gpu |
| maximum runtime is 8 hours; job likely to start quickly with GPUs |
test |
test |
| allows people to use idle resources of lab-purchased environments | serial_requeue |
serial_requeue |
| allows people to use idle resources of lab-purchased environments | gpu_requeue |
(n/a) |
| private environments purchased by specific labs | PI/Lab nodes |
PI/Lab nodes |
For more details about the partitions on CANNON, see “Slurm partitions“.
For more details about the partitions on FASSE, see “SLURM and Partitions“.
Queuing (waiting for jobs to start)
Submitting a job to run on a cluster is similar to when your group arrives at a restaurant and asks for a table. The properties of your group – number of people, special needs such as a highchair or space for a wheelchair, etc. – correspond to your job’s resource requirements. If a restaurant table that meets your needs is available, your party is seated right away and your meal experience begins. If an appropriate table is not yet available, your party waits until one is available.
RCE
When you submitted a job to the RCE, the Condor job scheduler compared the resources you requested against the cluster’s available resources. If the resources were available, Condor started your job. If the resources were not available, your job waited in the queue until they were available.
Here’s a peek into some of what Condor was doing on your behalf.
Condor had these states for a job (plus a few others that are more obscure):
PENDINGThe job is waiting for resources to become available to run.ACTIVEThe job has received resources and the application is executing.SUSPENDEDThe job has been suspended. Resources which were allocated for this job may have been released due to some scheduler-specific reason.DONEThe job completed successfullyFAILEDThe job terminated before completion because of an error, user-triggered cancel, or system-triggered cancel.
CANNON and FASSE
When you submit a job to CANNON or FASSE, the Slurm job scheduler compares the resources you are requesting (including the partition) against the cluster’s available resources for that partition. If the resources are available, Slurm starts your job. If the resources are not available, your job waits in the queue until they are available.
Slurm has these states for a job:
PENDINGJob is waiting to start. Jobs with high resource requirements may spend significant time PENDING.RUNNINGJob is currently running.SUSPENDEDJob execution has stopped and resources were released for other jobs. Job can be resumed, returned to running.COMPLETINGJob is nearly finished. Resources are being released. (The timing of your Slurm command to check on your jobs has to be impeccable to see this state.)COMPLETEDJob finished normally.FAILEDJob ended with some problem.CANCELLEDJob was explicitly terminated by you or a system administrator.
Fairshare is an integral part of how Slurm schedules jobs to run. See Fairshare and Job Accounting for the technical details. Your lab group’s Fairshare score is part of Slurm’s determination of how quickly your job and the other lab group members’ jobs start after you submit it. Here is a brief overview:
Your lab group’s Fairshare score is a value between 0 and 1. It was set to 1 when your lab group first got access to CANNON or FASSE to ensure that your first jobs would run soon after you submitted them. When you run jobs on the cluster, your Fairshare score drifts lower, towards the 0.5 average. It rises and falls depending on how you are using the cluster. It gets “worse” (goes towards 0) when you use cluster resources and it gets “better” (goes toward 1) when you are less active. Even if your Fairshare score hits 0, your jobs will still run, but only when there are no other jobs competing with your resource needs.
Submitting a lot of jobs means that your next job(s) may not start quickly in order to be kind to other users of the cluster.
Your PI is billed for your use of the cluster. In simple terms, 1 unit of billing consists of 1 core and 4 GB of memory. When your job completes, you’re charged for the maximum number of cores and the maximum amount of memory (rounded up to 4 GB chunks) that it used.
Cluster Comparison Table
This table compares the RCE, CANNON, and FASSE clusters with highlighted differences in yellow.
| Cluster name | RCE | CANNON | FASSE |
| “Age” | oldest | middle | newest |
| VPN access | vpn.harvard.edu | vpn.rc.fas.harvard.edu | vpn.rc.fas.harvard.edu |
| VPN realm | none (uses your HarvardKey email address) |
@fasrc | @fasse |
| Data Security Level (DSL) | DSL1, DSL2, and DSL3 | DSL1 and DSL2 | DSL1, DSL2, and DSL3 |
| Color-coding of dashboard | (no dashboard) | Red | Blue-gray |
| Graphical desktop / OOD | Yes, via NX web or client | Yes, via web | Yes, via web |
| Command line access | Yes | Yes | Yes |
| Batch jobs? | Yes | Yes | Yes |
| Batch processor / scheduler | Condor | Slurm | Slurm |
| File transfer | Filezilla | Filezilla, Globus | Filezilla, Globus |
| Storage capacity in home directory |
2 GB | 100 GB, not accessible from FASSE | 100 GB, not accessible from CANNON |
| Group or project storage | Yes | Yes not accessible from FASSE |
Yes not accessible from CANNON |
| Time limits for jobs | None | Yes 8 hours on some partitions 7 days on other partitions no limit on the unrestricted partition and on lab-specific partitions |
Yes 8 hours on some partitions 7 days on other partitions no limit on lab-specific partitions |
| Internet access | Yes | Yes | Yes, with appropriate proxy settings (see Accessing the Internet in FASSE Cluster – FAS Secure Environment) |
| Operating system | Red Hat Enterprise Linux (RHEL) | CentOS | CentOS |
Bookmarkable Section Links
- 1 If you have never used the RCE
- 2 Goal of this document
- 3 If you have been using the RCE
- 4 Transferring files
- 5 Main Differences between RCE and CANNON/FASSE
- 5.1 VPN (Virtual Private Network)
- 5.2 Username and Password
- 5.3 Partitions and Time limit for jobs
- 5.4 User interface
- 5.5 Home directories, Storage Tiers, Annual Costs, and Backups
- 5.6 Job Scheduler
- 5.7 Partitions
- 5.8
- 5.9 Queuing (waiting for jobs to start)
- 5.10 Fairshare on CANNON and FASSE
- 5.11 Cluster Comparison Table